Group test: Nvidia Quadro, Titan and GeForce RTX GPUs

Which Nvidia GPU is best for your DCC work? Jason Lewis puts four of the firm’s powerful Turing-based GeForce RTX, Titan RTX and Quadro RTX graphics cards through a battery of real-world benchmark tests.
Originally posted on 11 October 2019. Read our recent review of the GeForce RTX 2080 Ti here.
In our latest hardware review, we are going to look at Nvidia’s current RTX GPUs. What started out as a review of a single professional-class GPU gradually evolved into a larger group test of Nvidia’s current consumer and workstation cards, plus one of AMD’s rival Radeon Pro workstation GPUs for reference. Some of the cards have appeared in previous single-GPU reviews on CG Channel; others are completely new.
I have mentioned this in my last few reviews, but it’s worth reiterating: PC technology has evolved at a feverish pace in the past couple of years compared to the rest of the decade. Nvidia’s Pascal and Turing GPU architectures offered huge performance improvements over previous generations, as did AMD’s Vega architecture. The RDNA architecture in AMD’s new Navi GPUs also looks to be a significant update.
In this group test, we are pitting all of the Nvidia GPUs from the past few CG Channel reviews against one another: the Titan RTX, Titan V, GeForce GTX 1080 and GeForce GTX 1070. In addition, we have three newcomers: the Quadro RTX 5000, Quadro RTX 4000 and GeForce RTX 2080. For comparison, we have one AMD GPU: the Radeon Pro WX 8200. I hope to revisit these tests with AMD’s RDNA GPUs later this year.
Jump to another part of this review
Technology focus: GPU architectures, memory types and APIs
Technology focus: consumer vs workstation cards
Specifications and prices
Testing procedure
Benchmark results
Performance breakdowns for each card
Other questions: how much difference does RTX ray tracing really make?
Other questions: how well does DCC performance scale on multiple GPUs?
Other questions: how well does rendering scale across both CPU and GPU?
Other questions: how much memory do you need on your GPU?
Verdict
Technology focus: GPU architectures, memory types and APIs
Before we discuss the cards on test, let’s run through a few of the technical terms that will recur throughout the course of this review. If you’re already familiar with them, you may want to skip ahead.
Nvidia’s current GPU architecture features three types of processor cores: CUDA cores, designed for general GPU computing; Tensor cores, introduced in the previous-generation Volta cards, and designed for machine learning operations; and RT cores, new in its RTX cards, and designed for ray tracing calculations.
The RT cores are Nvidia’s hardware implementation of DXR, DirectX 12’s new DirectX Raytracing API. While the firm has introduced limited support for DXR ray tracing on older GPUs, including those on test here, most software developers are focusing on the new RTX cards. While we are starting to see more widespread adoption of RTX in games, implementing support for new hardware in CG applications is a much slower process. You can read a summary of DCC tools and game engines currently supporting RTX here.
It’s important to note that comparing core counts is a reasonable way to judge the probable relative performance of different Nvidia cards, but not to compare Nvidia cards with those from AMD, which have a different architecture, and group processing cores into ‘compute units’ instead.
The two firms also differ in the APIs they support for GPU computing: while both AMD and Nvidia support the open standard OpenCL, Nvidia focuses primarily on its own CUDA API. OpenCL has the advantage that it is hardware-agnostic, but CUDA is more widely supported in DCC applications, particularly renderers.
Another key specification when it comes to GPU rendering is on-board memory: both a card’s total capacity, and the type of memory it uses. Most of the cards on test here use some variant of GDDR (Graphics Double Data Rate) memory – either GDDR6 or the older GDDR5X and GDDR5 – but some use HMB2 (High Bandwidth Memory), which is specifically designed with memory bandwidth in mind.
Technology focus: consumer vs workstation cards
Another key distinction between the cards on test is that between professional workstation GPUs and their consumer gaming counterparts. While consumer cards are typically much cheaper, the drivers for workstation cards are optimised for graphics applications, including Adobe’s Creative Cloud tools and popular DCC and CAD packages like 3ds Max, Maya, AutoCAD and SolidWorks. These optimisations provide greater stability when compared to their desktop counterparts.
In addition, manufacturers offer more extensive customer support for professional cards: in many cases, workstation cards are the only ones officially certified for use with DCC or CAD software. Essentially, professional cards are targeted at users who rely not only on speed, but on stability and support. You may get adequate performance out of a consumer card – but during crunch periods, when you need reliability as well as performance, a professional GPU offers greater peace of mind.

Specifications and prices
Titan RTX
The Titan RTX is joint fastest of Nvidia’s Turing GPUs, with compute performance identical to the top-of-the-range Quadro RTX 6000 and Quadro RTX 8000. It has 24GB of GDDR6 memory, 4,608 CUDA Cores, 576 Tensor cores, and 72 RT cores. While the Titan GPUs began as gaming cards, Nvidia now markets them for content creation, although they lack the ISV certification and support of standard workstation cards.
Read our detailed review of the Nvidia Titan RTX here
Titan V
The Titan V and its workstation counterpart, the GV100, are the only two non-datacenter GPUs to use Nvidia’s Volta architecture. The Titan V has 12GB of HBM2 memory, 5,120 CUDA cores, and 640 Tensor cores. It’s marketed at data science and AI development rather than content creation, but since it has display outputs, we’re throwing it into the mix.
Quadro RTX 5000
The first of our newcomers is the Quadro RTX 5000. It sits in the middle of Nvidia’s range of Turing workstation cards, below the super-high-end Quadro RTX 8000 and Quadro RTX 6000, and above the mid-range Quadro 4000. It has 16GB of GDDR6 memory, 3,072 CUDA cores, 384 Tensor cores and 48 RT cores.
Quadro RTX 4000
The next of our newcomers is the Quadro RTX 4000. Although the entry-level GPU among Nvidia’s Turing workstation cards, its specs make it more of a mid-range card. It has 8GB of GDDR6 memory, 2,304 CUDA cores, 288 Tensor cores, and 36 RT cores. It is also the only single-slot Turing GPU: the others are dual-slot.
GeForce RTX 2080
The last of our newcomers is the GeForce RTX 2080. It sits almost at the top of Nvidia’s range of Turing consumer cards, just below the GeForce RTX 2080 Ti and GeForce RTX 2080 Super. It has 8GB of GDDR6 memory, 2,944 CUDA Cores, 368 Tensor cores, and 46 RT cores. We were testing Nvidia’s own Founders Edition card.
GeForce GTX 1080
Even though its architecture is now a generation old – two if you count the very limited release of the Volta GPUs – the GeForce GTX 1080 is still widely used for content creation. It sat almost at the top of Nvidia’s range of Pascal consumer cards, behind the GeForce GTX 1080 Ti. It has 8GB of GDDR5X memory and 2,560 CUDA cores. We were testing the Asus Founders Edition.
GeForce GTX 1070
Also still widely used, the GeForce GTX 1070 sat towards the top of Nvidia’s range of Pascal consumer cards, and is widely regarded as the ‘little brother’ of the GeForce GTX 1080. It has 8GB of GDDR5 memory and 1,920 CUDA cores. Again, we were testing the Asus Founders Edition.
Radeon Pro WX 8200
The only AMD card in our round-up is the Radeon Pro WX 8200. It sits towards the top of AMD’s current Radeon Pro WX series of workstation cards, behind the Radeon Pro WX 9100. It has 8GB of HBM2 memory and 56 compute units.
Read our detailed review of the AMD Radeon Pro WX 8200 here
| Consumer GPUs | |||||
|---|---|---|---|---|---|
| Titan RTX | Titan V | GeForce RTX 2080 |
GeForce GTX 1080 |
GeForce GTX 1070 |
|
| Manufacturer | Nvidia | Nvidia | Nvidia | Nvidia | Nvidia |
| Architecture | Turing | Volta | Turing | Pascal | Pascal |
| GPU | TU102 | GV100 | TU104 | GP104 | GP104 |
| Clock speed (base, MHz) |
1350 | 1200 | 1515 | 1607 | 1506 |
| Clock speed (boost, MHz) |
1770 | 1455 | 1710 | 1733 | 1683 |
| Memory | 24GB | 12GB | 8GB | 8GB | 8GB |
| Memory type | GDDR6 | HBM2 | GDDR6 | GDDR5X | GDDR5 |
| Memory bandwidth (GB/s) |
672 | 652 | 448 | 320 | 256 |
| CUDA cores | 4608 | 5120 | 2944 | 2560 | 1920 |
| Compute units | – | – | – | – | – |
| Tensor cores | 576 | 640 | 368 | 0 | 0 |
| RT cores | 72 | 0 | 46 | 0 | 0 |
| Compute power (FP32, Tflops) | 16.3 | 14.9 | 10.1 | 8.9 | 6.5 |
| Compute power (FP64, Gflops) |
510 | 7450 | 315 | 277 | 202 |
| TDP | 280W | 250W | 215W | 180W | 150W |
| Price | $2,500 MSRP |
$2,999 MSRP |
$799 MSRP |
~$350-700 Used |
~$250-500 Used |
Used card prices based on www.newegg.com as of 8 October 2019.
| Workstation GPUs | |||
|---|---|---|---|
| Quadro RTX 5000 |
Quadro RTX 4000 |
Radeon Pro WX 8200 |
|
| Manufacturer | Nvidia | Nvidia | AMD |
| Architecture | Turing | Turing | Vega |
| GPU | TU104 | TU104 | Vega 10 |
| Clock speed (base, MHz) |
1620 | 1005 | 1200 |
| Clock speed (boost, MHz) |
1815 | 1545 | 1500 |
| Memory | 16GB | 8GB | 8GB |
| Memory type | GDDR6 | GDDR6 | HBM2 |
| Memory bandwidth (GB/s) |
448 | 416 | 512 |
| CUDA cores | 3072 | 2304 | – |
| Compute units | – | – | 56 |
| Tensor cores | 384 | 288 | – |
| RT cores | 48 | 36 | – |
| Compute power (FP32, Tflops) | 11.2 | 7.1 | 10.8 |
| Compute power (FP64, Gflops) |
349 | 223 | 672 |
| TDP | 265W | 160W | 230W |
| Price | $2,299 MSRP |
$899 MSRP |
$999 MSRP |
Testing procedure
The test system for this review was a BOXX Technologies APEXX T3 workstation sporting an AMD Ryzen Threadripper 2990WX CPU, 128GB of 2666MHz DDR4 RAM, a 512GB Samsung 970 Pro M.2 NVMe SSD, and a 1000W power supply. Its specifications should ensure that there were no bottlenecks in graphics performance while running the benchmark scenes, aside from the GPUs on test.
Read a detailed review of the BOXX APEXX T3 workstation here
The benchmarks were run on Windows 10 Pro for Workstations, and were broken into four categories:
Viewport and editing performance
3ds Max 2019, Blender 2.80 (beta), Fusion 360 2109, Maya 2019, Modo 12.1v2, SolidWorks 2019, Substance Painter 2018, Unity 2018.2.0b9, Unreal Engine 4.21, Unreal Engine 4.22 (viewport ray tracing)
Rendering
Blender 2.80 (beta, using Cycles), Cinema 4D R20 (using Radeon ProRender), Indigo Renderer 4 (IndigoBench), LuxCoreRender 2.1, Maverick Studio Build 380.660, Redshift 2.6 for 3ds Max, SolidWorks 2019 Visualize, V-Ray Next for 3ds Max
Other benchmarks
Premiere Pro CC 2018 (video encoding), Quake 2 RTX (ray tracing), Unreal Engine 4.21 (VR performance)
Synthetic benchmarks
3DMark, Cinebench R15
In the viewport and editing benchmarks, the frame rate scores represent the figures attained when manipulating the 3D assets shown, averaged over 8-10 testing sessions to eliminate inconsistencies. They are further subdivided into pure viewport performance – when panning, rotating or zooming the camera – and performance when manipulating an object. Viewport performance is largely dependent on the GPU; manipulation performance depends on both GPU and CPU, and is typically much slower.
In all of the rendering benchmarks, the CPU was disabled, so only the GPU was used for computing.
Testing was performed on a single 32” 4K display, running its native resolution of 3,840 x 2,160px at 60Hz.
Benchmark results
Viewport and editing performance
The viewport benchmarks include many of the key DCC applications – both general-purpose 3D software like 3ds Max, Blender and Maya, and more specialist tools like Substance Painter – plus CAD package SolidWorks and the two leading commercial game engines, Unity and Unreal Engine.
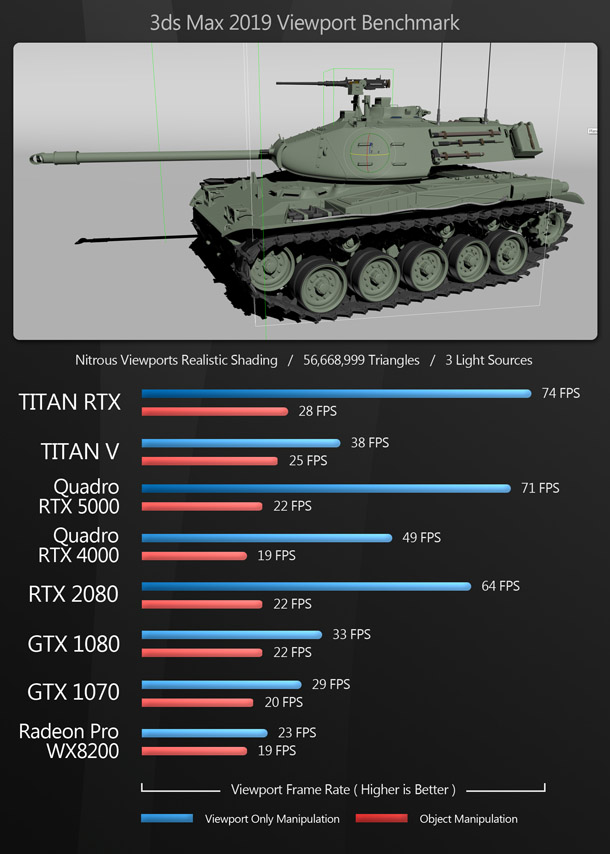
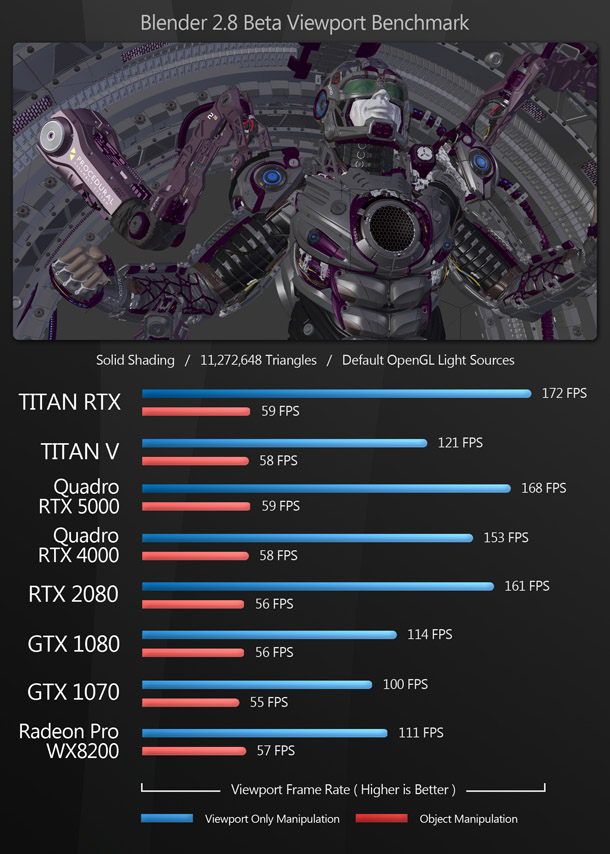
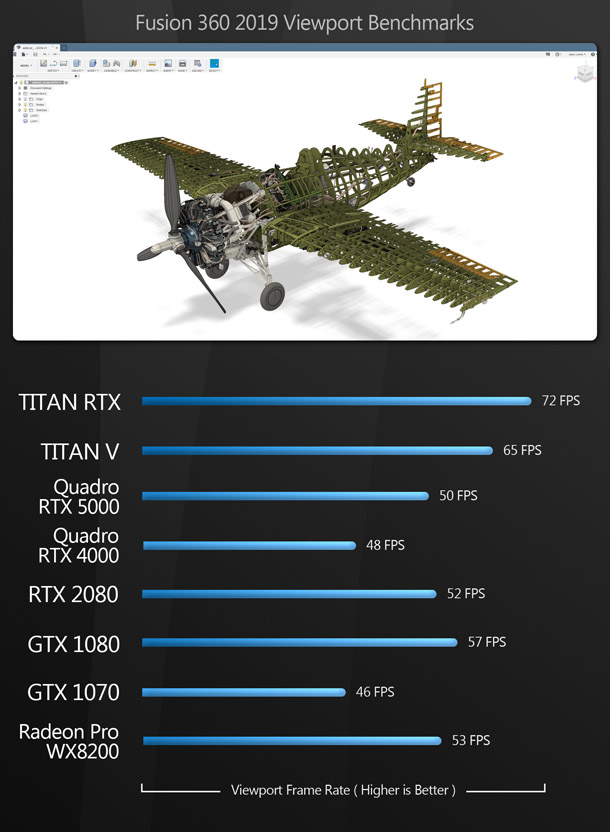

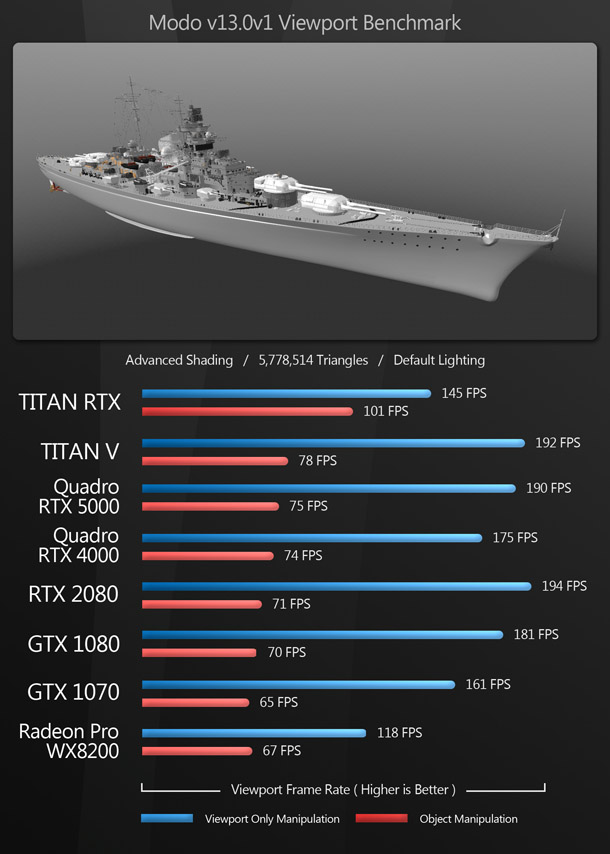
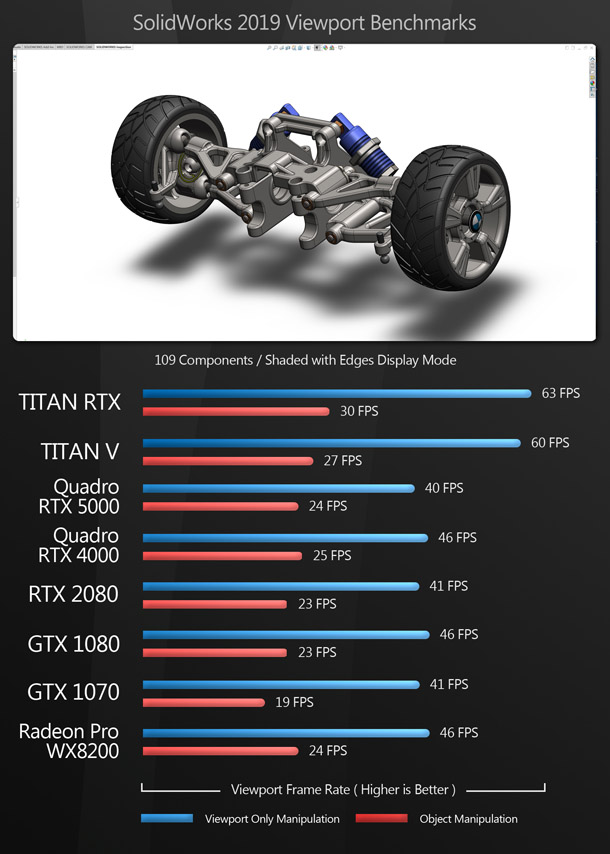
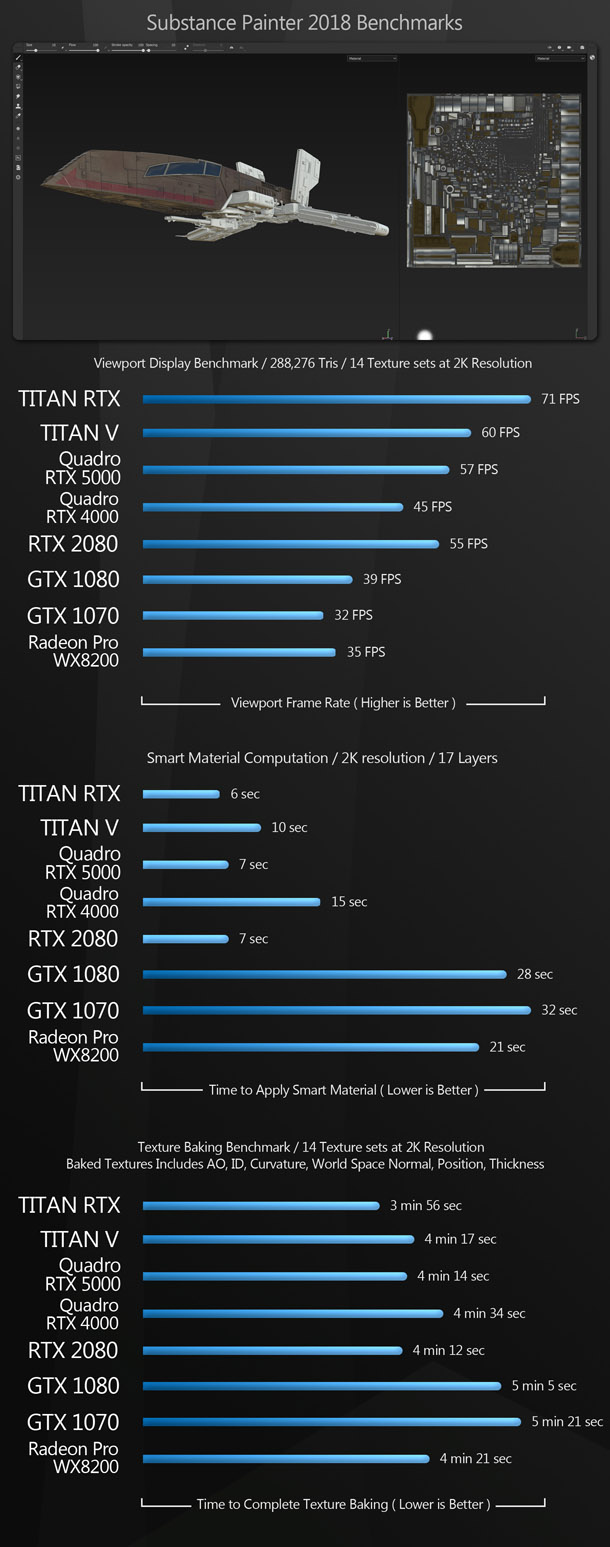



Rendering
The rendering benchmarks comprise both the native render engines of DCC and CAD applications and popular third-party renderers like Redshift and V-Ray. Some of them don’t support OpenCL, only CUDA, which is why the AMD GPU doesn’t register a score for all of them.
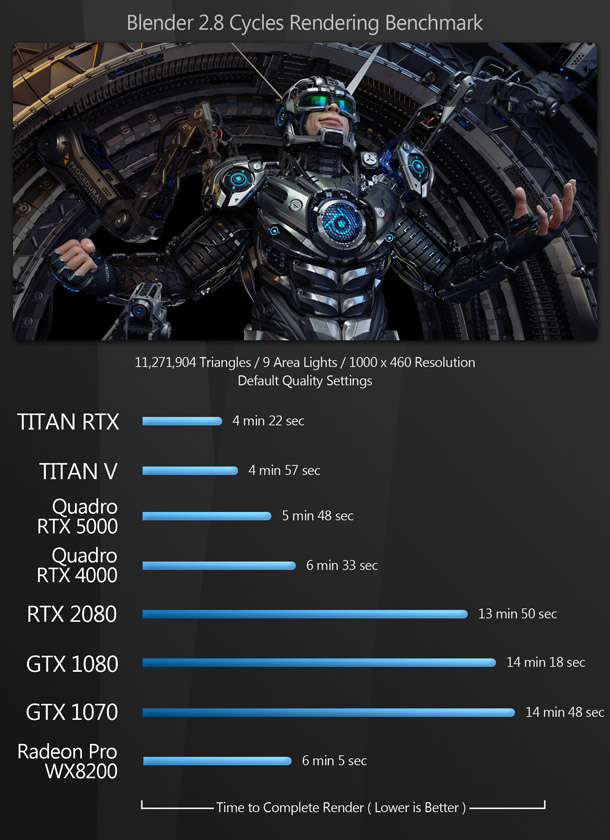
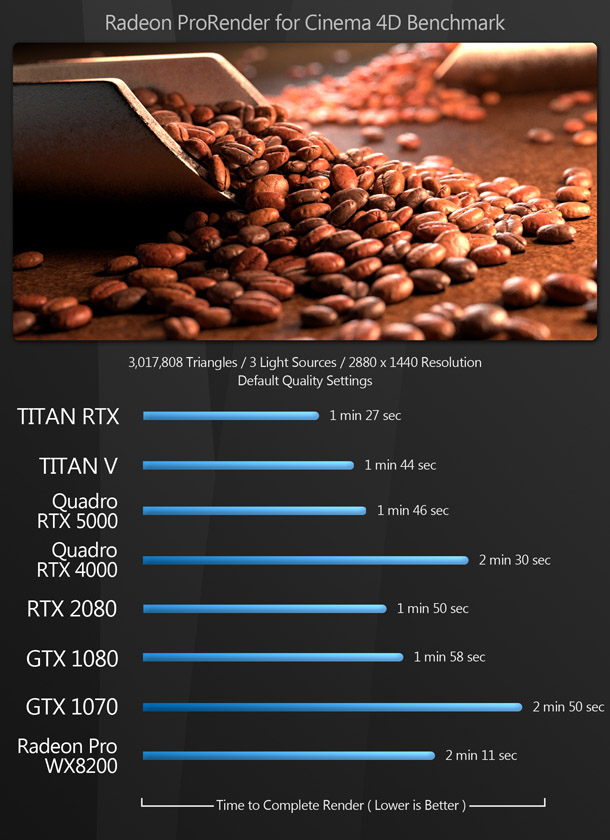
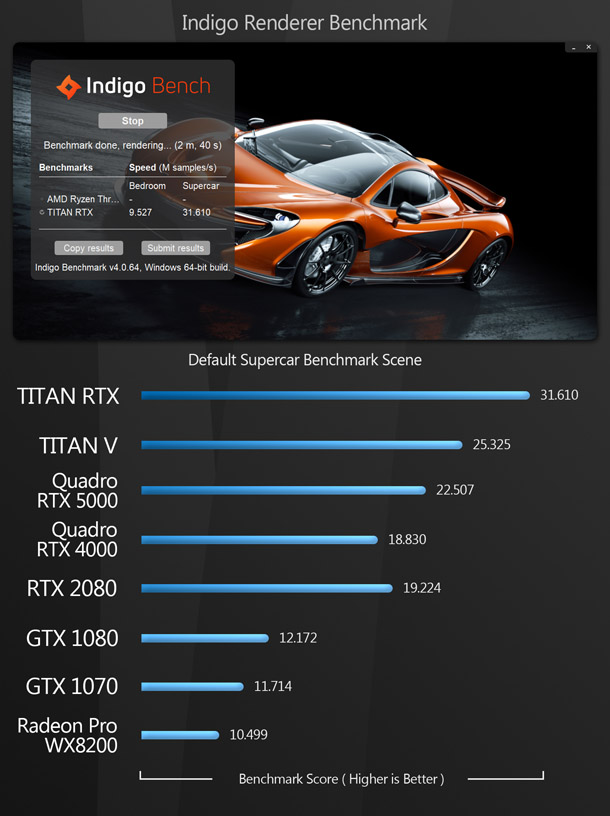

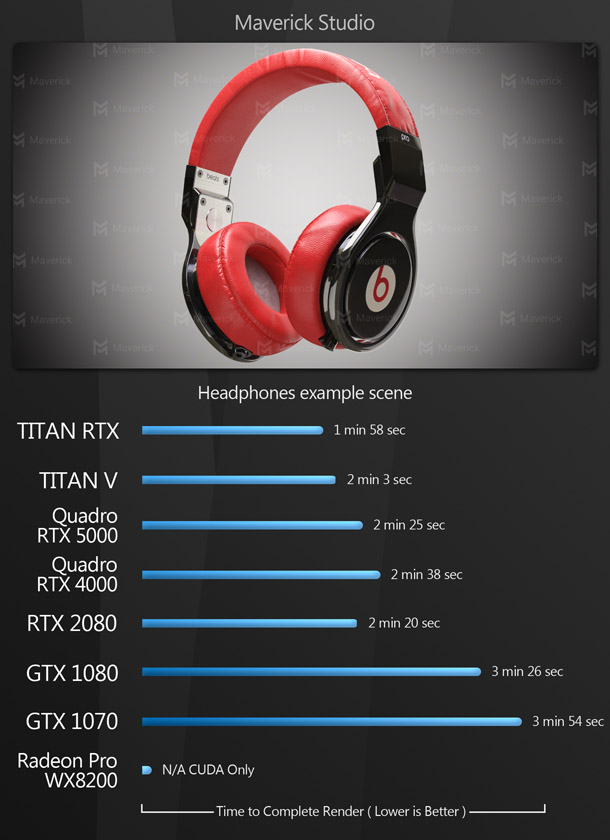
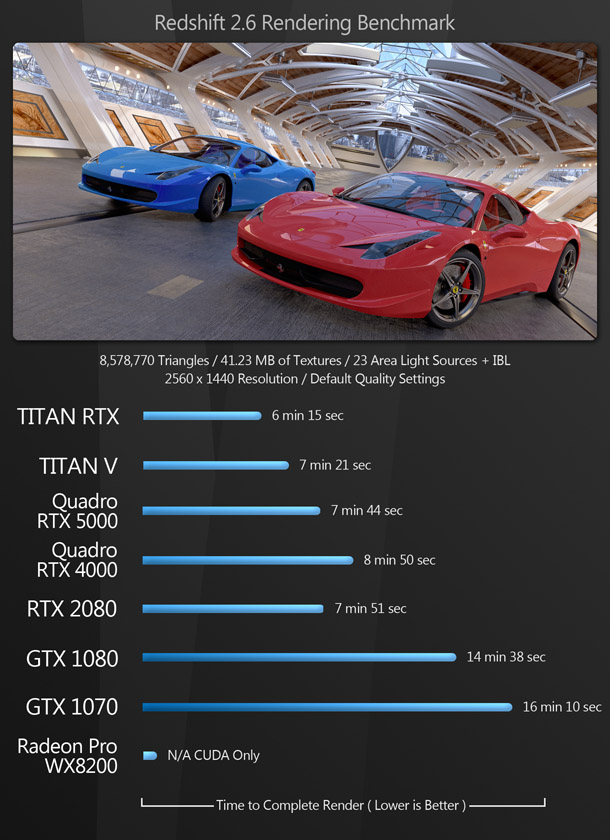
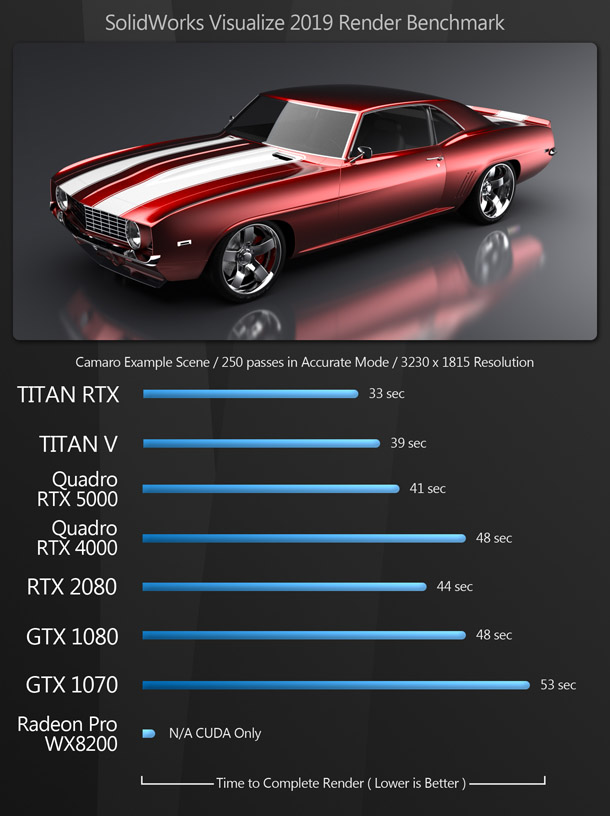

Updated 16 October 2019: The V-Ray benchmark image has been updated to remove the score for the AMD Radeon Pro WX 8200. See the notes on OpenCL support in V-Ray Next in the comments section.
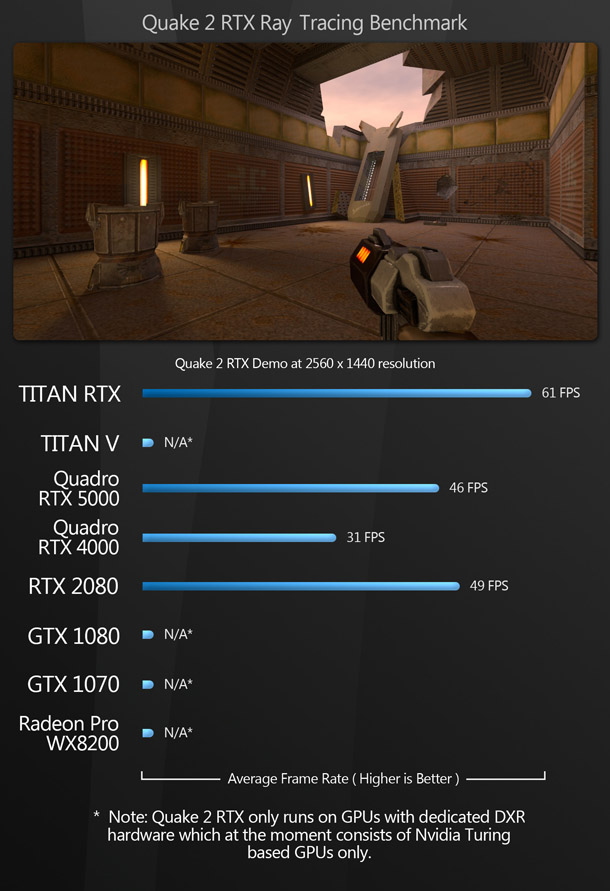
Other benchmarks
Next, we have a set of benchmarks designed to measure more specialised tasks, like video encoding and VR performance. For the RTX cards only, I also included Quake 2 RTX, Nvidia’s RTX-enabled reworking of the 1997 first-person shooter, intended as a proof of concept for hardware-accelerated ray tracing.
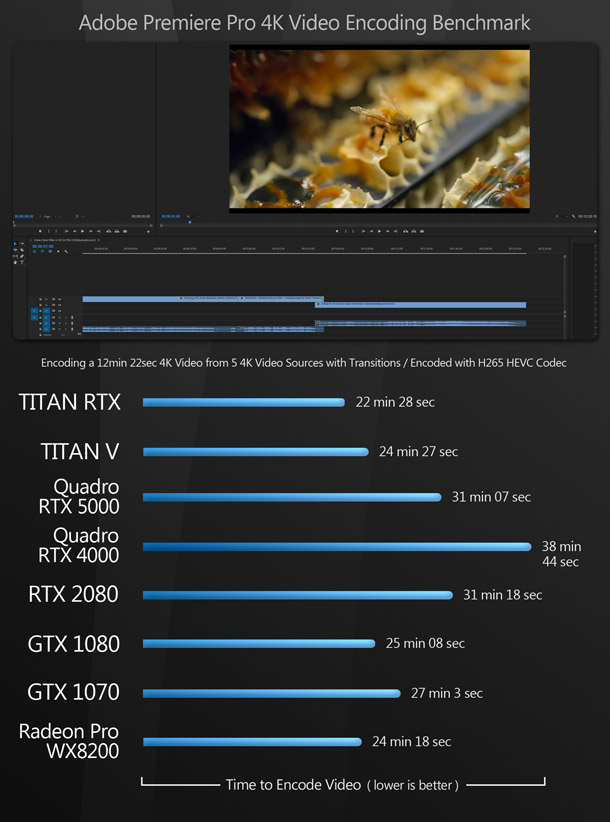

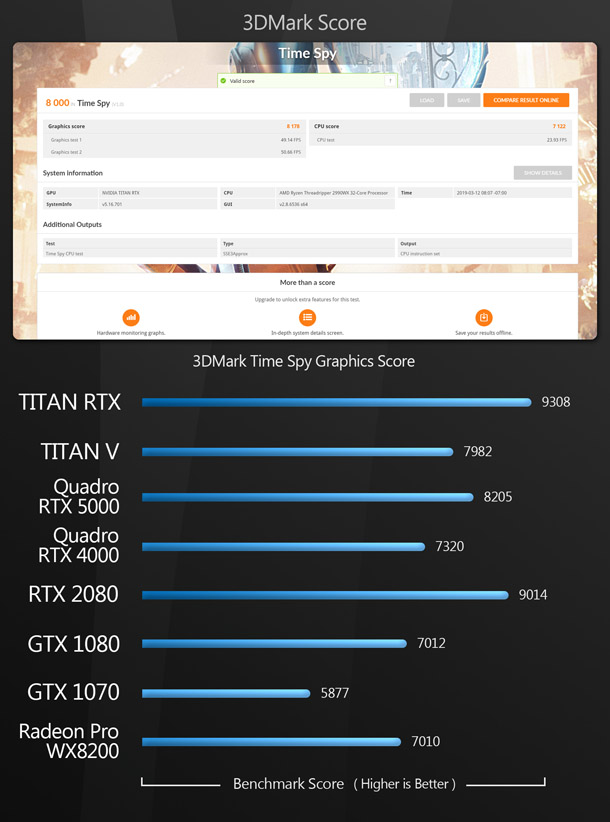
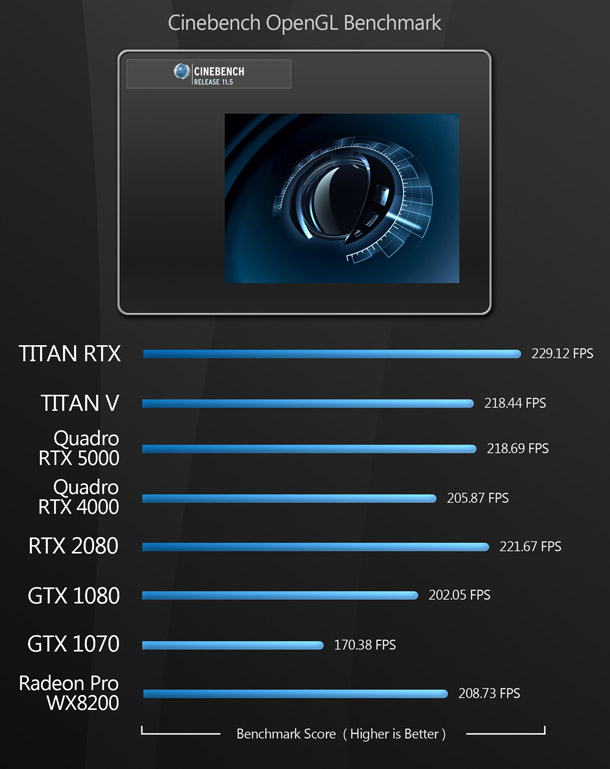
Synthetic benchmarks
Finally, we have two synthetic benchmarks. I don’t feel that synthetic benchmarks accurately predict how a GPU will perform in production, but they do provide a standardised way to compare the cards on test with older models, since scores for a wide range of GPUs are available online. In the case of Cinebench, I’m using the previous version of the software, Cinebench R15, as it is the last one to include a GPU benchmark.
Performance breakdowns for each card
With the number of GPUs on test, and the array of benchmarks that each has been put through, there is a lot of data to digest. As a result, I am going to do something different to my previous reviews. Instead of compiling all the results and offering a conclusion as a whole, I am going to present a performance summary and my conclusions for each GPU individually.
Titan RTX
The Titan RTX is currently one of the fastest GPUs you can buy. It wins in every single test here. Compared to the top-of-the-range Quadro RTX 6000 and 8000 – both of which have the same key specs, but more graphics memory – it’s a steal, but at $2,500, that performance still doesn’t come cheap.
If you are looking for a GPU to power the viewports of your DCC software and you don’t need ISV certification, the Titan will definitely get the job done. However, unless you are working with extremely complex assets, it’s probably more GPU than you need. Once more applications begin to make use of the ray tracing capabilities of the Turing GPUs, more of a case could be made for the Titan RTX as a viewport GPU, but by then, there will probably be something newer and faster out.
One situation that may justify the purchase of a Titan RTX is GPU computing, especially rendering. The Titan RTX offers fantastic rendering performance, and with its 24GB of graphics memory, can render very large scenes. This will become more important over the coming year as more renderers with native RTX ray tracing support come out of beta.
Titan V
The Titan V is a speciality card aimed at data mining and those working with AI and machine learning. It still performs well with DCC software, but falls behind the Titan RTX in all tests. Since it costs $500 more, has only half the graphics memory, and lacks the Titan RTX’s dedicated ray tracing hardware, it just doesn’t make sense to buy the Titan V for entertainment work.
Quadro RTX 5000
For me, the Quadro RTX 5000 is the most appealing of the current generation of Quadro cards. If you are a DCC professional who needs a workstation GPU and the benefits they provide, its performance isn’t too far off that of the Titan RTX, and its 16GB of graphics memory will handle most current assets.
So why not just pay a couple of hundred dollars more and get a Titan RTX? One possible reason is that the Quadro RTX 5000 is a professional card, with the software certification and support that that brings; the Titan RTX is not. Another is that GeForce and Titan cards use a dual axial cooling solution, whereas the Quadro cards have a more traditional single fan. This is better for multi-GPU set-ups and rack-mounted systems, as hot air is vented out of the back of the card, not recirculated inside the workstation chassis. For systems that run under high loads for extended periods, this may be significant.
Quadro RTX 4000
The Quadro RTX 4000 is a peculiar product. Like the Quadro RTX 5000, it will only appeal to users who need the ISV certifications and support offered by workstation GPUs, but compared to its more expensive sibling, its performance is all over the board. In many of the benchmarks, it isn’t far behind the RTX 5000, and in one case actually outperforms it, but in others – particularly those based around game engines like Unity and Unreal Engine – it is significantly worse.
However, with an MSRP of $899, the Quadro RTX 4000 is less than half the price of the RTX 5000. In situations in which the performance of the two cards is consistently close, such as GPU rendering, it offers good performance at a much lower cost.
But if you are considering a Quadro RTX 4000 over a RTX 5000, one thing to be aware of is that the RTX 5000 supports NVLink, Nvidia’s latest GPU interconnect technology, while the RTX 4000 does not. In my opinion, being able to link two Quadro RTX 5000 cards and access 32GB of graphics memory during GPU rendering makes the RTX 5000 much more versatile.
One other interesting feature of the RTX 4000 is its single-slot form factor. Many reviewers, like Nvidia itself, tout this as one of the RTX 4000’s best features, making claims like: ‘Massive GPU performance in a small package.’ My response would be: ‘Yes, but why does it need to be small?’ Unless a lot of DCC professionals are building Mini-ITX graphics workstations (I’ve never seen one myself), I don’t really see the need for a single-slot professional graphics card. Even rack-mount enclosures typically have space for dual-slot GPUs: vertically in 3U and 4U chassis and horizontally in 2U chassis. The single-slot design of the RTX 4000 is barely adequate to keep it cool – even under moderate workloads, it runs quite hot. With a dual-slot cooler, it could potentially be clocked higher, increasing performance.
GeForce RTX 2080
In these tests, the GeForce RTX 2080 performs similarly to the Quadro RTX 5000. This is to be expected as, from a hardware standpoint, they are very close. Both use variants of the Turing TU104 GPU and have similar compute performance. The biggest difference between them is memory: the GeForce RTX 2080 has 8GB of RAM, whereas the Quadro RTX 5000 has 16GB. Both support NVLink, but it isn’t clear whether in the GeForce RTX 2080 this is just for multi-GPU scaling in games, or whether it can also be used to share GPU memory when rendering, as with the Titan RTX and Quadro RTX GPUs.
With an MSRP of $799, the RTX 2080 is expensive for a consumer card, but if you are a DCC professional – assuming that you don’t need the other benefits provided by a workstation card, and 8GB of memory isn’t an obstacle – it offers similar performance to the Quadro RTX 5000, at a much lower price point. Its successor, the GeForce RTX 2080 Super, released shortly before this review, may offer better performance still.
GeForce GTX 1080
The GeForce GTX 1080 was, at the time of its launch, a powerhouse of a GPU, delivering a massive performance increase over the previous-generation GTX 980 and GTX 980 Ti. A little over three years on, it still performs well. In many tests, it comes close to the GeForce RTX 2080, and in a few, it actually outperforms it. Even in tests where the GTX 1080 falls some way behind, it still offers pretty good performance. It lacks the dedicated AI and ray tracing cores of the RTX GPUs, but given the limited number of applications that currently make use of them, I wouldn’t say that this is a deal-breaker.
The only thing that keeps me from saying, “Who needs RTX? Go get a bunch of GTX 1080s if you are on a budget,” is the cost. Even used, GTX 1080 cards still sell for around $500, which makes it hard to recommend a three-year-old GPU when you can get a current-generation GeForce RTX 2070 for around the same price. I haven’t tested an RTX 2070 myself, but they’re said to be a little faster.
The one exception I will make in recommending a GeForce GTX 1080 for current DCC work is if you can find a used one cheap. On rare occasions, I do see them on eBay for $250-300, and at that price, they’re a bargain. If you do find a used one, just make sure it wasn’t used in a cryptocurrency mining rig, as these have often been stressed for extended periods of time, and can be prone to failure.
GeForce GTX 1070
Like the GeForce GTX 1080, the GeForce GTX 1070 is a previous-generation gaming card that holds up quite well today. I know several game development studios where the GTX 1070 is still the standard GPU used in artists’ workstations. Its performance isn’t too far behind the GTX 1080, and it possesses the same 8GB of RAM, although it has similar issues with cost: at around $300, a refurbished GTX 1070 is around the same price as the newer GTX 1660 Ti, and not much cheaper than the current-gen GTX 2060. Again, I haven’t tested either card myself, but their performance is said to be similar or better, although here, the extra 2GB of memory in the GTX 1070 may be a selling point when it comes to GPU rendering.
The used GPU market is also more favourable to the GTX 1070: although prices fluctuate wildly, they can be had for as little as $150-200, which makes them very good value indeed. As with the GTX 1080, if you do buy used, make sure the card wasn’t used for cryptocurrency mining, as this can significantly shorten its lifespan.
Radeon Pro WX 8200
The only AMD GPU in this round-up, the Radeon Pro WX 8200, is one of the company’s newer current-gen workstation cards. It occupies a similar price point to the Quadro RTX 4000 and trades blows with it in the benchmarks, with honours shared evenly in those tests that both cards are able to complete. However, with its MSRP of $999, the Radeon Pro WX 8200 is $100 more expensive; and without CUDA support – the reason that it cannot complete all of the GPU rendering tests – or the dedicated ray tracing hardware of the new Nvidia cards, it just isn’t as versatile.
The only exceptions would be if you are a Maya user, or do a lot of video encoding with Premiere Pro, as in these benchmarks, the Radeon Pro WX 8200 takes a significant lead over the Quadro RTX 4000. The same is true in the Unity and Unreal Engine editor, so a case could also be made for it there, although most content creators working with real-time engines use consumer gaming GPUs.
Other questions: how much difference does RTX ray tracing really make?
As I mentioned earlier, Nvidia’s RTX GPUs incorporate dedicated real-time ray tracing hardware. This has the potential to greatly change the way DCC professionals work. But how does it perform in the real world?
In this round-up, the only one of the benchmarks to make use of this new hardware is Unreal Engine – and as you can see from those figures, performance suffers greatly when ray tracing is enabled. I have seen several videos of users using the ray tracing features of UE4 with good frame rates, but those are at much lower screen resolutions. On a 4K display, even the mighty Titan RTX struggles to go over 30fps, and that is with a very simple scene that is only using ray tracing for shadowed lights, and reflections. (Screen-space AO, translucency and GI were disabled.) In Unreal Engine, RTX-enabled ray tracing is still officially in beta, so hopefully we will see speed increases in future, but at present, it isn’t an automatic win.
Other questions: how well does DCC performance scale on multiple GPUs?
All of the benchmarks in this review were run on a single-GPU configuration. So how much faster are multi-GPU set-ups? There are two aspects to this: compute performance and viewport performance.

Compute performance – for example, during final-quality rendering – scales extremely well across multiple GPUs. Above, you can see the results of our GPU rendering benchmarks when run on a single Quadro RTX 5000 card, and when run on two Quadro RTX 5000 cards. The resulting increase in speed ranges from 65% in the case of Radeon ProRender to 97% in the case of V-Ray GPU.
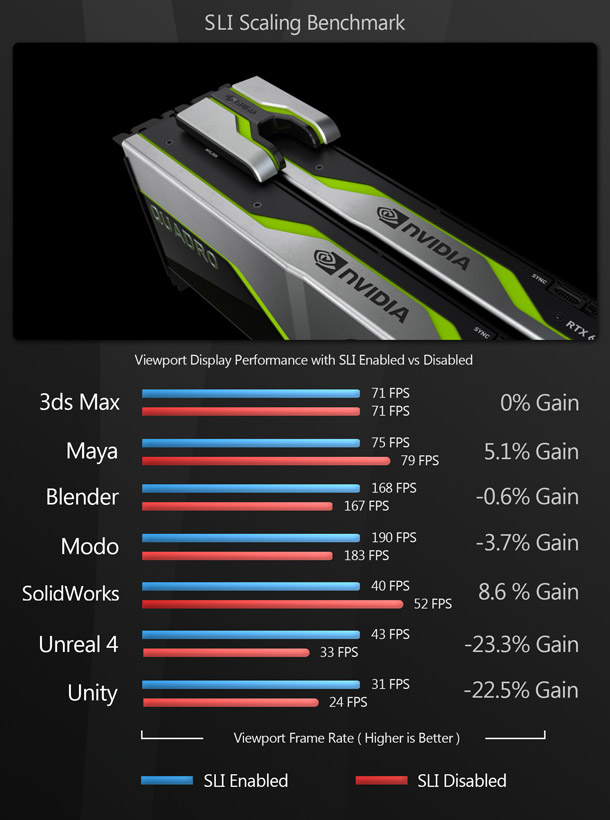
So what about viewport performance? Set-ups using SLI, Nvidia’s previous-gen technology for linking GPUs, can get you much better frame rates in games, but can they do the same for the viewports of DCC apps? I’ve had quite a few people ask me this, so I tested using two Quadro RTX 5000 GPUs, enabling SLI via the PCI Express bus on the BOXX system’s ASRock X399 Taichi motherboard. The last time I tried using SLI with DCC applications was in 2011, and those tests revealed that, at the time, it had little benefit for graphics work.
Fast forward nine years, and unfortunately, the same holds true. With SLI enabled, viewport performance in all of the DCC applications tested here showed very little change, going up by a few frames in some cases and in others actually going down. However, I didn’t have access to an NVLink bridge – Nvidia’s newer GPU interconnect technology – during benchmarking, so this may be something to revisit.
Other questions: how well does rendering scale across both CPU and GPU?
For years, final-quality rendering was done on the CPU. It is only recently that the industry has moved towards using GPUs for rendering. But while GPU renderers are typically faster than their CPU-only counterparts, they often lack advanced features. We are now starting to see a shift to what I believe will become the norm: hybrid CPU/GPU renderers. Both CUDA and OpenCL, the main frameworks for GPU computing, make it possible to use both CPU and GPU in parallel. So how does this affect performance?

As you can see, when you add the processing power of the test system’s AMD Ryzen Threadripper 2990WX CPU to that of the GPU, there is a significant increase in rendering speed. Combining the CPU with multiple GPUs results in a further increase. While this benchmark used Blender’s Cycles engine, all of the renderers used here can be set to use both CPU and GPU, with the exception of Redshift and Maverick Studio.
Other questions: how much memory do you need on your GPU?
Memory is a crucial factor when deciding which GPU to buy for DCC work. Although software developers are working on support for texture streaming and out-of-core rendering, both of which should alleviate the problem to some extent, in most cases, if your scene is larger than the memory available, GPU compute performance takes a massive hit. So how much GPU memory is enough GPU memory?
Some people feel that the 6-8GB of RAM now standard in consumer graphics cards and lower-end workstation cards is more than enough. While that may be the case for gaming and entry-level DCC tasks, it isn’t always true. One counter-example is working with large open worlds in Unity or Unreal Engine. While completed games usually rely on optimisations to stream parts of the world in and out of memory based on scripted sequences or player position, when working in the editor, artists like to have most, if not all, of the world loaded. This can easily fill up the available memory.
Another good counter-example is texturing software like Substance Painter. If you work with high-resolution textures, multiple texture sets, and lots of layers, your GPU memory will fill up real quick. With 14 texture sets, each at 4K resolution, and multiple smart materials in each, the finished version of the Moldy Crow model used in these benchmarks exceeds even the 16GB of memory available on the Quadro RTX 5000. The only card on which it fits into GPU memory is the Titan RTX.
One final use case for high-RAM GPUs is architectural visualisation. Models of complex buildings like stadiums can be insanely complex, as can architectural masterplans. If you regularly work with this kind of dense CAD data, consider buying a card with as much GPU memory as possible.
Verdict
What can we take away from all this data? It’s difficult to make definitive statements about which GPU is ‘best’ – as we have seen, it comes down to your personal needs as a content creator, and your budget. If you need the ISV certification and customer support provided by a workstation GPU, you will be looking only at these products; if not, you will probably be looking only at cheaper consumer cards.
However, there are some generalisations that can be made. Firstly, unless you can find a previous-generation Pascal GPU really cheap, you’re better off going with a current-generation Turing card. Second, given the importance of graphics memory for GPU rendering, buying the GPU with the largest pool of VRAM you can afford will give you the most flexibility, regardless of whether you’re buying a consumer or workstation card.
With only one AMD card in this round-up, I can’t make any recommendations about about the firm’s GPUs as a whole: only note that the Radeon WX 8200 falls behind Nvidia’s RTX cards in these tests. However, with AMD’s new RDNA architecture now beginning to roll out in its latest cards – and with Nvidia also launching its refreshed GeForce RTX ‘Super’ GPUs – that could change in future.
So while I can’t tell you which specific GPU to buy, I can say that it is a great time to be a digital content creator. Never have we had such a range of great hardware for creating content quickly and efficiently, and I continue to look forward to what the future brings us!
Read more about Nvidia’s GPUs on its website
Read more about AMD’s GPUs on its website
About the reviewer
Jason Lewis is Senior Environment Artist at Obsidian Entertainment and CG Channel’s regular reviewer. In his spare time, he produces amazing Star Wars fan projects. Contact him at jason [at] cgchannel [dot] com
Acknowledgements
I would like to give special thanks to the following people for their assistance in bringing you this review:
Gail Laguna of Nvidia
Sean Kilbride of Nvidia
Peter Amos of AMD
Marissa Sandell of Edelman
Cole Hagedorn of Edelman
Redshift Rendering Technologies
Otoy
Bruno Oliveira on Blend Swap
Reynante Martinez
Stephen G Wells
Adam Hernandez
Thad Clevenger